千元横测GPT、DeepSeek、Xiaomi、MiniMax的最强模型,我找到了跟Agent们的绝配
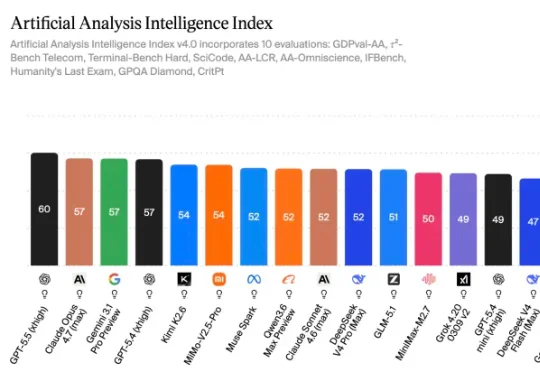
千元横测GPT、DeepSeek、Xiaomi、MiniMax的最强模型,我找到了跟Agent们的绝配上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。
来自主题: AI产品测评
11336 点击 2026-05-03 08:49